We track over 24,000 open source AI artifacts across the stack. This map scores 452 of them in depth on three independent axes:
- Openness (graded 0–5 against openness frameworks, not a yes/no: the Model Openness Framework for models, OSI classes for software, with data and hardware analogues)
- Adoption (real usage, not stars)
- Capability (benchmarks where they exist, feature coverage where they don’t)
Every score is sourced. The remaining 24,400 are the uncategorized long tail, tracked by usage signal but not yet scored. The openness framework descends directly from the 2024 Columbia Convening on Openness in AI.
Table of contents
- Introduction
- Notebooks
- Discovery and scoring
- The three axes
- Maturity stages
- Gaps
- The openness verdict
- Limitations
- Choices made in the visualization
- Contributors
Introduction
To create the map, we used both a discovery step (to find the universe) and a more rigorous scoring and enrichment step (to grade each product). The taxonomy we use to categorize products descends directly from the 2024 Columbia Convening on Openness in AI.
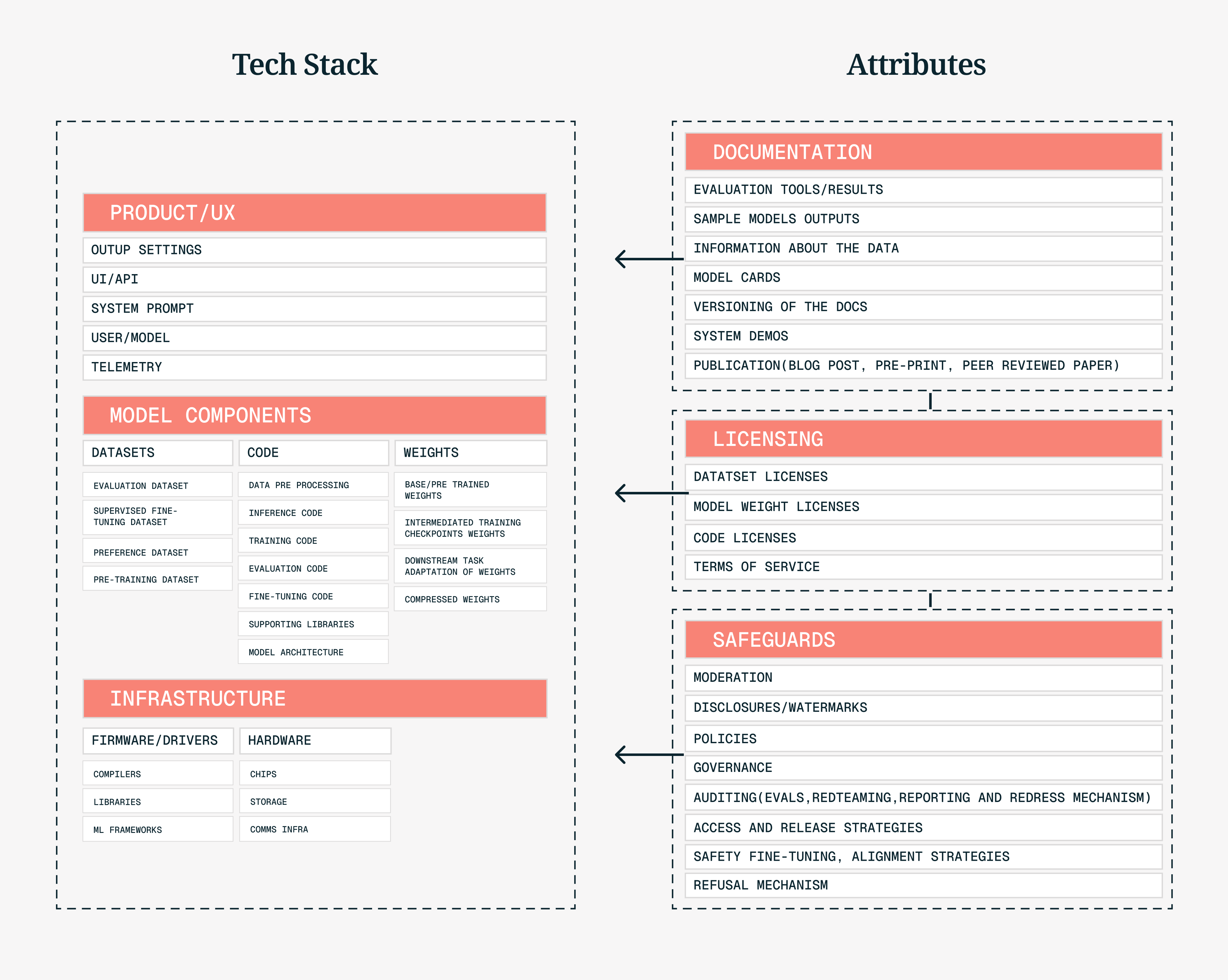
General-purpose AI system stack & Dimensions of Openness from the 2024 Columbia Convening on Openness in AI.
The framework has two levels of analysis:
- Each product is scored on three axes: openness, adoption, and capability.
- Each category is rolled up from its products' scores into a maturity stage from 0 (Void) to 5 (Mature), plus a set of gaps naming what its open ecosystem still lacks.
Notebooks
Besides this gap map, the underlying data is also available to explore directly through our notebooks. Each notebook lets you explore a specific slice of the dataset. You can find the notebooks here:
All notebooks are also available on GitHub at currentai-org/os-ai-map, where you can inspect the underlying code, or adapt them for your own analysis.
Discovery and scoring
The discovery step identifies the universe of candidate products and artifacts; the scoring step enriches and grades a curated subset of them.
The discovery step draws on large-scale open data from the software supply chain compiled by Open Source Observer. We seeded it from Chip Huyen's Good AI List, a catalog of AI-focused repositories, then broadened it through analysis of the Hugging Face Hub, the Open LLM Leaderboard, the AI Incident Database, package registries and SBOMs, and academic and industry publications. From these sources we assembled approximately 24,821 candidate products, including 15,375 GitHub repositories, 6,428 models and datasets, and 2,823 package entries. We ranked the candidates by adoption signal (repository stars, package and model downloads, and related measures) and enriched the most prominent first.
The scoring step enriched and graded 421 products in depth: 266 software tools and libraries, 85 models, 50 datasets, and 20 hardware projects, produced by 228 organizations. We organize these products into 14 categories across 3 layers of the stack (model components, product / UX, and infrastructure), though we do not cover the stack exhaustively. The remaining 24,400 artifacts constitute the uncategorized long tail: they are tracked by usage signal but carry no openness, adoption, or capability score until they are researched and cited.
The three axes
We grade each product on three axes, each answering a different question:
- How open is it? (openness)
- How used is it? (adoption)
- How good is it? (capability)
The grading is deliberately multi-source. Each axis pulls from a different family (adoption from registries, OpenRouter, and trackers; capability from benchmark leaderboards and papers; openness from primary vendor and repository sources), so no single source determines a product's standing.
Every value also records what the source showed and when we accessed it. Across the scored set this comes to 1,606 primary citations spanning 275 distinct source domains. We excluded any product we could not verify against a primary source rather than estimating it. The result is auditable and reproducible, not something to take on trust.
Axis 1: Openness
Openness has two fields. The first, the class, is a categorical label drawn from the Model Openness Framework and OSI license taxonomy (for example open_source, open_weights, open_core, source_available, restricted, gated, documented_only, closed). The class serves as the cross-category normalizer: it is the field to use when positioning a product on an openness spectrum. The second, the score, is a 0–5 grade with a component-level breakdown: weights, data, code, checkpoints, and license for models; license tests for software; access, license, and documentation for datasets.
The score is graded relative to what is achievable within a product type, so the same number does not carry the same meaning across categories. A pretrained model at 2 is genuinely restricted, because the openness range for models is compressed: open weights typically land near 3, and a 5 requires a fully open pipeline of the Pythia or OLMo kind. A deployment tool at 2 sits elsewhere entirely. The raw 0–5 score should therefore be read as a within-type detail, not as a cross-category coordinate.
For analysis across the whole stack, we collapse the class vocabulary into three buckets:
- Open: open_source, open, open_core, open_hardware
- Open-ish: open_weights, source_available, gated, open_toolchain
- Closed: restricted, documented_only, closed, documented
Hardware uses its own openness vocabulary, parallel to the software and model classes: open schematics with an open toolchain (open_hardware); proprietary silicon but an open SDK with public datasheets and retail availability (open_toolchain); public datasheets but proprietary design or firmware (documented); and private or NDA-gated availability (restricted).
The openness framework descends from the 2024 Columbia Convening on Openness in AI and its follow-on work, and from the Model Openness Framework. License, weights, data, and code are each judged separately rather than reduced to a single binary. Primary vendor sources (the blog posts and documentation of Anthropic, Google, OpenAI, Meta, Mistral, NVIDIA, Microsoft, AWS, and others) are cross-checked against the actual LICENSE file in the repository and the model card on the Hugging Face Hub, with arXiv and general web search used to corroborate. The distinction between "open weights" and "open source" is not incidental to the map; it is the distinction the map exists to make.
Axis 2: Adoption
Adoption is graded 1–5 and measures real usage (downloads, active users, and deployments) rather than repository popularity. GitHub stars are treated as a weak last-resort signal and never raise a product above level 3.
The sources differ by product type. For repositories we use GitHub stars, forks, and developer activity; for models and datasets, Hugging Face downloads and likes; for packages, registry download statistics (PyPI via pypistats.org, pepy.tech, and pypi.org, together with npm). Relative usage across models is estimated from OpenRouter's per-model token-share leaderboard. For the large closed consumer surfaces, where first-party usage figures are unavailable, we rely on traffic and monthly-active-user trackers such as Business of Apps and DemandSage.
We recognize that adoption metrics can be gamed or manipulated, and welcome community feedback on the sources and methods used to compute them.
Axis 3: Capability
Capability is graded 1–5, and each grade records its basis: a community benchmark where one exists, a structured feature grid where none does, or null where capability is not a meaningful axis for the product type.
Capability means different things for a model, a tool, and a dataset, so capability grades are comparable within a category and not across categories. Benchmark evidence is drawn from Artificial Analysis (its Intelligence Index), LMArena / Chatbot Arena, Epoch AI (including FrontierMath, GPQA Diamond, and SWE-bench), Scale's SEAL leaderboards, Vals AI, LLM-Stats, and the EleutherAI evaluation-harness lineage behind the Open LLM Leaderboard. For specialized categories we use domain benchmarks (for example ANN-Benchmarks and Qdrant's published figures for vector databases, and SWE-bench aggregators for coding agents), and in some cases we return to the original arXiv papers for methodology and reported results.
Maturity stages
We place every category on a maturity stage from 0 (Void) to 5 (Mature), computed deterministically from its products' scores, in two steps: first we score each product's maturity, then we read the category's stage off how many of its open products are mature.
Step 1: the product maturity score. Each product receives a single score on a 1–5 scale, a per-category weighted blend of its adoption and capability grades:
score = (w_adopt · adoption + w_cap · capability) / (w_adopt + w_cap)
The weights vary by category, because the two axes do not matter equally everywhere: adoption is weighted more heavily for end-user surfaces such as UI & API (0.7 adoption to 0.3 capability), and capability more heavily for the model categories (0.3 to 0.7); the two weights sum to one. Where capability is not a meaningful axis (for datasets, for instance), the product is graded on adoption alone, and a product with no adoption signal at all receives no score and is left out of its category's stage. A product is mature only when its blended score reaches 4.5 of 5, a deliberately demanding bar: because the map already curates the most prominent products, a lower bar would call almost everything mature.
Step 2: the category stage. Only fully open products advance a category's stage. Open-ish products (open weights, source-available, and the like) are used solely to detect the openness gap below; crediting them would blur the line between open source and open weights that the map exists to draw. The ladder therefore measures the health of the genuinely open ecosystem:
- Stage 5: Mature Open Ecosystem. Four or more mature fully open products: redundant and resilient.
- Stage 4: Competitive Open Ecosystem. At least one mature fully open product, but fewer than four.
- Stage 3: Viable Alternatives. No mature fully open product, but the best fully open option is strong.
- Stage 2: Emerging Alternatives. No mature fully open product; the best fully open option is promising but limited.
- Stage 1: Open Experiments. Fully open options exist but are weak on both axes.
- Stage 0: Void. No usable open option exists.
The exact cutoffs (four mature products for Stage 5, the 4.5 maturity bar, and best-fully-open score bands of 3.5, 3.0, and 2.0 dividing the lower stages) are deliberate, tunable parameters, reviewed when the scoring rubric or curation density changes materially. Not every category needs to reach Stage 5; redundancy matters more in some parts of the stack than others.
Gaps
Openness is treated as an axis orthogonal to maturity: a category can hold strong, widely adopted options that are simply not fully open. Each category therefore carries a set of zero or more gaps, derived from the same metrics as the stage:
- Void: no usable open option exists at all.
- Capability: the best fully open option is not capable enough to be useful.
- Adoption: a capable fully open option exists but is under-adopted.
- Maturity: open options exist, and at least one may be mature, but the ecosystem lacks the depth and redundancy of a mature one (too few mature fully open products).
- Openness: capable, adopted options exist, but the mature ones are not fully open. This is the orthogonal flag, and it can co-occur with the others.
A fully mature ecosystem carries no gaps. The set is extensible: further gap types, such as maintenance or bus-factor risk, can be added as the underlying signals become available, without changing the staging logic.
Here are two illustrations:
- The base/pretrained-models and fine-tuned/chat-models categories both carry an openness gap: capable, well-adopted options exist, but the mature ones are not fully open.
- The inference-code category, by contrast, has mature, competitive, well-adopted open source options (vLLM, llama.cpp, SGLang) but few of them; this is a maturity gap, signaling an ecosystem that depends on a small number of projects continuing to do well.
At present 4 of the 14 categories in the map carry an openness gap.
The openness verdict
Each category also carries a one-line verdict: which openness tier (open, open-ish, or closed) leads among its strongest products, or competitive when none clearly does. It is a convenience summary on top of the openness scores already described; the per-category counts always show the full open / open-ish / closed mix, so a category that is open in its long tail but closed at the top stays visible.
Limitations
Several constraints bound the present results and are stated plainly. The scored set is a curated sample of the most prominent products, not a census; the 24,400 artifacts in the long tail are tracked by usage signal only and remain ungraded. Composition and "known-build" relationships are curator-asserted from documentation rather than mined from deployment telemetry. Product descriptions, and therefore keyword-based lookup, are English-centric. The openness class-to-spectrum mapping is the analysts' editorial judgment, not a law of nature, and some distinctions collapse in it by design. Finally, as noted above, the raw 0–5 openness and capability scores are within-type grades and should not be compared directly across categories.
Choices made in the visualization
We chose to visualize products in the gap map starting from a maturity score of 4. While only products with a maturity score of 4.5 and above are included in gap analysis and category maturity assessments, products scoring between 4.0 and 4.5 are still considered sufficiently mature to be displayed on the map for contextual and visual completeness.
Contributors
Our work and methodology builds on the 2024 Columbia Convening on Openness in AI, which was written by the following authors: Adrien Basdevant, Camille François, Victor Storchan, Kevin Bankston, Ayah Bdeir, Brian Behlendorf, Merouane Debbah, Sayash Kapoor, Yann LeCun, Mark Surman, Helen King-Turvey, Nathan Lambert, Stefano Maffulli, Nik Marda, Govind Shivkumar, Justine Tunney.
We're looking for collaborators
If you want to review products, improve our methodology, or add your tools, reach out.